
The AI Citation Mystery Behind Bot Access

Your competitor gets cited in ChatGPT responses. You don't. Same story with Perplexity, Claude, and Google AI. The content quality is comparable, but AI systems consistently ignore your website.
Many assume it’s a content or reputation problem and sometimes it is. But in our experience at Performiq, the most overlooked and limiting factor is technical infrastructure. AI visibility depends on multiple interconnected technical layers, and issues at any level can block the entire system. We always start by auditing and removing technical access barriers first because if AI systems can’t reach or interpret your content, nothing else matters.
We walk you through the critical technical layers that directly impact AI discoverability — not just for SEO, but for brand visibility in AI-powered search results.
Why Can't AI Find Us?
When AI assistants never cite your content even for topics you cover extensively, the problem is usually technical access, not content quality.
Can AI crawlers actually reach your content?
The Access Control Problem
The first technical barrier: robots.txt configuration. This file acts as a bouncer for your website. If it's blocking AI crawlers, no amount of content optimization matters.
Common blocking patterns:
This line blocks all crawlers, including both traditional search engines and AI-specific bots. No amount of content optimization will help if your site tells all bots to stay out.
But even when general access is allowed, many sites unintentionally block AI crawlers due to missing or overly restrictive user-agent rules. Unlike Googlebot or Bingbot, many newer AI crawlers are treated as unknown and denied access by default.
Common AI Crawlers You May Be Blocking:
Check yoursite.com/robots.txt. Test your robots.txt rules in robots.txt tester. And remove any blocks that may be silently excluding AI-specific user agents.
From the Performiq Playbook: Even if your robots.txt is correctly configured, server-level security rules can still silently block AI crawlers, returning status codes like 403 Forbidden or 418 I'm a teapot. These blocks don’t show up in most SEO audits and require log analysis or user-agent testing to detect.
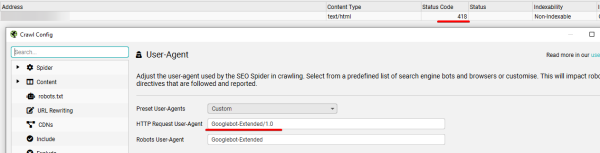
In this example, our client’s website returned a 418 status code specifically to the Googlebot-Extended user agent. This block isn't defined in the robots.txt file but occurs at the server configuration level, preventing AI systems like Google’s Gemini from accessing the site entirely. These types of silent blocks are often overlooked and can severely limit AI visibility, even when standard SEO settings appear correct.
The Rendering Reality Problem
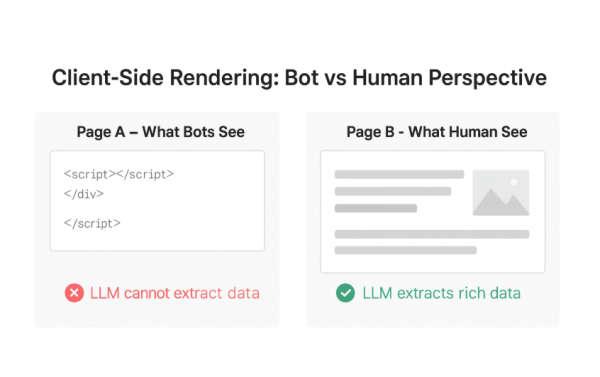
Access granted doesn't mean content accessible. AI systems must receive the final rendered content after JavaScript execution. Many sites fail here because they use client-side rendering (SPA/JavaScript) where critical content only becomes available after JS execution.
The invisible content problem: Your site loads perfectly for human visitors, but AI crawlers receive empty HTML shells. Prices, product details, contact information, and key descriptions exist only in JavaScript-generated content.
- Raw HTML Test: View page source (Ctrl+U) and search for your main content text
- Google Search Console: Check URL inspection tool's rendered screenshot vs. raw HTML
- AI Crawler Simulation: Use tools to extract pure text content
Technical solutions for rendering problems:
Here are the technical solutions we implement depending on your setup:
1. Server-Side Rendering (SSR) Implementation:
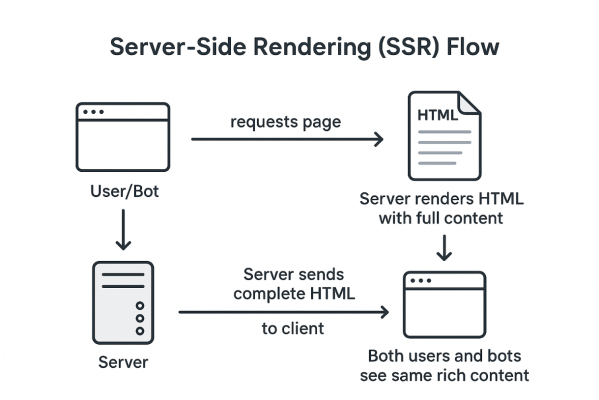
For React, Vue, or Angular apps, SSR ensures the full HTML is generated on the server and sent to bots and users alike — not just an empty shell.
- Next.js for React applications
- Nuxt.js for Vue.js sites
- Angular Universal for Angular apps
- Generate complete HTML on server before sending to user
2. Dynamic Rendering for Existing SPAs:
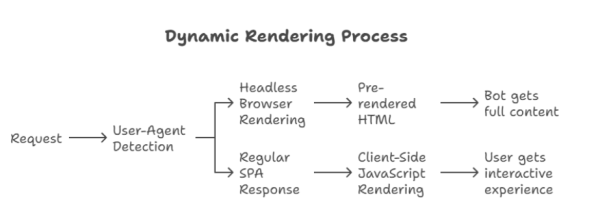
If you're running a single-page application (SPA) and can’t fully migrate to SSR, dynamic rendering is a practical fix.
- Implement Prerender.io or similar middleware
- Configure server to detect bot requests (User-Agent analysis)
- Serve static HTML to crawlers while maintaining SPA for users
3. Essential robots.txt additions for rendering:
Allow access to resources needed for rendering
Don’t forget about Core Web Vitals
AI crawlers take technical performance into account when selecting sources. Slow-loading pages and poor Core Web Vitals reduce your chances of being cited. Mobile optimization is especially critical, as many AI systems primarily analyze the mobile version of your site.
Also, be aware of HTTP errors. Critical pages — such as category listings, product pages, FAQs, and contact pages — must consistently return a 200 OK status. Repeated 4xx or 5xx errors can exclude your site from AI consideration for weeks or even months.
The Information Architecture Problem
Your content is accessible and renderable, but AI systems still miss key information. This layer involves how content is structured for machine understanding.
AI systems don't read web pages like humans. They parse semantic structures, extract entities, and map relationships between concepts. Poor HTML hierarchy confuses these extraction processes.
Audit criteria for AI-readable structure:
- Single H1 per page with clear topic focus
- Logical heading hierarchy (H2 → H3 → H4)
- Semantic HTML tags (article, section, aside, nav)
- Meaningful alt attributes for images
- Structured lists for processes or features
- Tables for comparative data
From the Performiq Playbook: Do not assume that AI systems are reading your page correctly. You need to manually check whether they recognize your prices, offers, and key details. This is especially critical for SPA sites or other JavaScript-heavy pages where content can load inconsistently.
For example, if a product page shows two different prices, AI may choose the wrong one. That mistake could directly impact clicks and conversions.
The real challenge is that AI crawlers don’t just index content like traditional search engines — they interpret and answer questions based on what they see. If they misread your content, the advice or snippet they generate could be misleading.
That’s why we use manual testing: asking AI systems specific questions about a page (e.g., “What is the price of this product?”) to confirm whether they are interpreting the content accurately.
AI Visibility Diagnostic Checklist
To bring it all together, we’ve distilled our diagnostic process into a checklist. Use it to uncover the barriers that may be blocking AI systems from citing your content and take the first step toward stronger AI visibility.
Access Control
- Review robots.txt for overly broad blocks (User-agent: * Disallow: /)
- Check explicit disallowances for AI crawlers
- Test rules in a robots.txt tester
- Check for server-level blocks (403, 418, etc.) in logs or via user-agent testing
Rendering & Performance
- Test if content is visible in raw HTML (View Source, AI crawler simulation, GSC rendered view)
- Implement SSR
- If SSR isn’t possible, configure dynamic rendering
- Update robots.txt to allow rendering resources (*.js, *.css, /assets/*)
- Optimize Core Web Vitals: LCP, CLS, FID
- Verify mobile optimization, since many AI crawlers parse mobile-first
- Ensure critical pages (categories, products, FAQs, contacts) always return 200 OK
Information Architecture
- Use a single, clear H1 per page
- Maintain a logical heading hierarchy (H2 → H3 → H4)
- Use semantic HTML tags (article, section, nav, etc.)
- Add meaningful alt text to images
- Use structured lists for steps/features and tables for comparisons
Manual Testing
- Ask AI systems questions about your content (e.g., “What’s the price of this product?”)
- Confirm that AI interprets prices, offers, and key details correctly
- Pay special attention to SPA/JS-heavy sites with multiple prices or variable data
- Correct misinterpretations before they impact visibility or conversions
There are many opinions about how to earn AI citations — from content quality to brand authority to structured data. All of these play an important role. But in our experience, they only make an impact once the technical foundations are solid. AI systems need to reliably reach, render, and interpret your content before any other factors can work in your favor.
At Performiq, we integrate technical SEO with AI-focused visibility strategies to ensure your business isn’t left behind as search continues to evolve. If you’re ready to find out why AI overlooks your site — and how to change that — let’s talk.



